Week 4
Generalized linear models
Do more parameters help? Instead of estimating the probability of the rat’s actions by a logistic function of $\sum_i a_iX_i$ where $X_i$ is some function depending on $i$ steps ago (ex. the rat’s choice $i$ steps ago), what if we add in 2ns order terms $\sum_i a_iX_i + \sum_i b_iX_iX_{i+1}$ (ex. we might think there’s some “sticky” effect where doing something twice in a row would have more effect that each action contributing seperately). However, experiments suggest that there is no systematic contribution from higher-order terms.
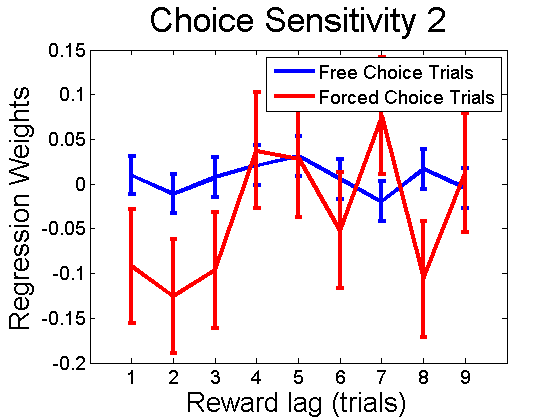
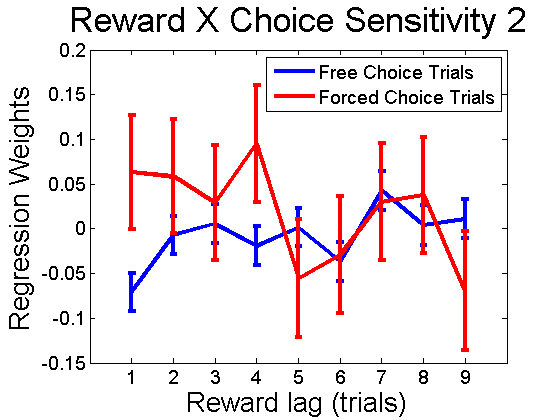
Markov models
So far, naive HMM’s (grouping the observed actions of the rat with reward/no reward) give garbage results. This is likely due to the fact that reward/no reward variable should be given separate treatment.
Variance between and within rats
A proposal: find the parameters for the linear model for each rat, and compare between rats; do they live in a low-dimensional space? Find the parameters for each session; do they change between sessions; are the sessions for a given rat clustered?
What metrics are we using to compare models?
Last time, we discussed using Random Forests as a baseline to compare against. But how are we doing that comparison? So far we have seen some measurements of normalized likelihood (an extension of log likelihood) and of area under the ROC curve. We need to standardize.
From a lot of reading this week, perhaps we should actually compute AIC and BIC for each model to compare:
- If we know the mis-classification cost for left and right, which seems to be the case here, then AIC is informative because it gives a goodness-of-fit for a specific mis-classification cost
- AUC is informative when you do not have a specific mis-classification cost in mind, e.g. if you are making medical diagnoses and do not know the false positive and false negative costs, but want to do well on average over all costs.
- AUC is useful for understanding one model’s discriminative ability, but is problematic when comparing models because it measures different things:
When is the area under the receiver operating characteristic curve an appropriate measure of classifier performance? D.J. Hand, C. Anagnostopoulos Pattern Recognition Letters 34 (2013) 492–495