More on Markov Models
Markov models with forced trials
First, let’s try to incorporate the forced trials into the Markov Model. The simplest way to do this is to remember whether or not a trial was forced. For every trial remembered, this doubles the state space, so we only show the graphs for lookback 1:
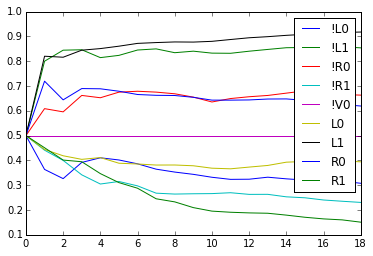
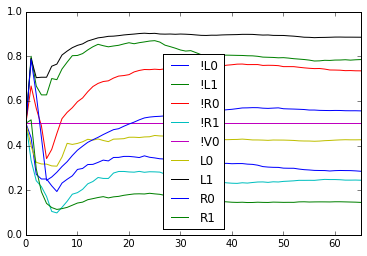
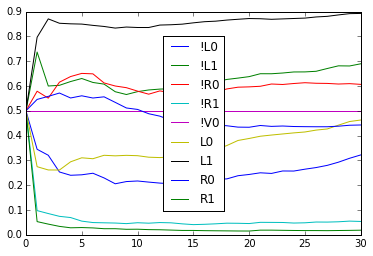
From this we see
- If a rat gets a reward on the previous trial, it is more likely to choose the same direction again if the previous trial was free.
- If a rat does not get a reward on the previous trial, it is more likely to switch if the previous trial was forced.
Both point to the idea that the rats perseverate only for free trials.
The normalized likelihoods are given by the following, for 3 rats and for lookback 0, 1, and 2.
| Lookback | Rat 1…………….. | Rat 2…………….. | Rat 3 |
|---|---|---|---|
| 0 | 0.500760344926605 | 0.5002506108385633 | 0.510379971539407 |
| 1 | 0.6095788354359929 | 0.5938565696250925 | 0.6683118861608311 |
| 2 | 0.6227237869918757 | 0.6119256242748692 | 0.692756631027587 |
Hidden Markov models
Hidden Markov models are more difficult to do inference on. Moreover, the number of states is unknown. One approach is to use Hierarchical Dirichlet Processes to learn the posterior distribution. The transition probabilities from a given state to another are modeled by a Dirichlet distribution, and the number of states need not be specified in advance.
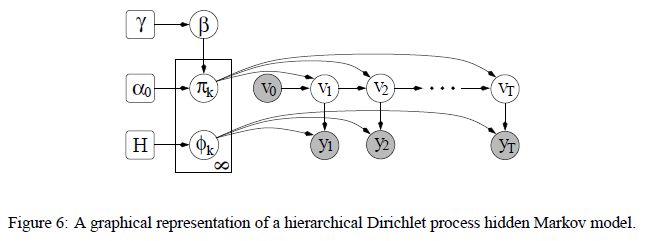
Each state is associated with a probability distribution over states it can transition to, as well as a probability distribution over observables. Thes probability distributions are determined by Dirichlet processes. It is hierarchical because the transition matrices associated with different states should share parameters, e.g., we’d expect some states to be consistently more popular than others.
This doesn’t quite yet fit our example. The $y_i$ are the rat’s actions. We need to add in the rewards $r_i$, and the fact that rewards influence the state transitions.
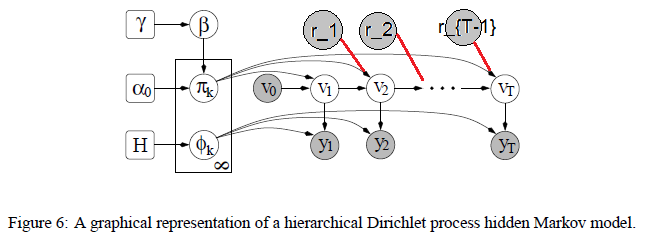
It makes more sense that the rat’s memory should be parameterized by a continuous variable, rather than a discrete one. It would be interesting if a discrete HMM could somehow “approximate” the continuous memory.